
I’ll use the SEO skill for the article workflow, then check the current SERP before drafting so the piece has real information gain instead of just matching the brief.The SEO skill routes this as a content/GEO job rather than a technical audit, so I’m pulling the GEO-specific guidance and then I’ll use live search for the ranking-page gap analysis.I’ll also check for any local SEO cache so I don’t ignore existing project context, then I’ll move to live SERP evidence.—
title: "GEO Tools for Agencies: Evaluation Scorecard for Multi-Brand Teams | maxaeo"
description: "Evaluate GEO tools for agencies with a practical scorecard for workspaces, prompt scale, reporting, and client-ready insights. Use it to shortlist."
slug: "geo-tools-for-agencies"
keywords: ["GEO tools for agencies", "ai visibility tool", "ai search monitoring", "brand mentions in chatgpt", "answer engine optimization", "generative engine optimization", "ai share of voice", "llm brand tracking", "ai citations", "ai reputation management", "get recommended by chatgpt"]
intent: "commercial"
author: "maxaeo"
schema: "Article"
datePublished: ""
dateModified: ""
GEO Tools for Agencies: Evaluation Scorecard for Multi-Brand Teams
GEO tools for agencies should be judged by one question: can they turn messy multi-client AI visibility data into repeatable client decisions? A single-brand dashboard may look polished in a demo, but agency work adds harder requirements: separate workspaces, prompt governance, competitor limits, exports, recurring reports, citation evidence, and clear next actions.
This guide gives you a practical buying framework, not another generic tool roundup. It is based on a live SERP scan, official Google guidance, public research on generative engine optimization, and an agency workload model you can reuse before taking vendor demos.
What are GEO tools for agencies?
GEO tools for agencies are platforms that monitor how AI answer engines mention, rank, cite, and describe multiple client brands across prompts, competitors, engines, and time. The best tools support multi-brand workspaces, prompt libraries, client-ready reporting, AI share of voice, citation tracking, and prioritized fixes.
In traditional SEO, an agency can often start with rankings, pages, backlinks, and Search Console data. In AI search monitoring, the unit of work is different. You are tracking answers to buyer questions across ChatGPT, Gemini, Perplexity, Claude, Copilot, Grok, Google AI Mode, and AI Overviews.
That means your evaluation should not stop at “Does the tool show brand mentions in ChatGPT?” The harder question is whether it helps a strategist explain why a client is missing from an AI-generated shortlist and what to fix next.
What current ranking pages cover and what they miss
Current ranking pages cover useful basics, but most underweight agency operations. In a June 18, 2026 live SERP scan for “GEO tools for agencies,” “best GEO tools,” and “AI visibility tools,” the visible top pages clustered into tool roundups, GEO explainers, and Google guidance pages.
The strongest ranking pages do three things well. They define generative engine optimization, explain metrics such as AI visibility score and share of voice, and compare vendors by engine coverage, pricing, citations, and reporting. For example, Search Engine Land defines GEO as the practice of positioning content so AI platforms cite, recommend, or mention a brand, and reports that 40–60% of cited sources changed month to month in a 2,500-prompt tracking set. Search Engine Land’s GEO guide is useful for the strategy layer.
Tool roundups add market context. Writesonic’s May 2026 roundup says it tested 10 GEO platforms against criteria such as engine coverage, closed-loop execution, data scale, customer evidence, and self-serve range. That is a good starting point, but it still leaves agencies with a practical gap: how many prompts can you run across six or twenty client accounts before the plan breaks? See Writesonic’s GEO tools roundup for an example of the current comparison-page pattern.
Google’s own documentation adds an important constraint. Google says there are no special technical requirements for AI Overviews or AI Mode beyond being indexed and eligible for Search snippets, and it also says structured data should match visible page content. That makes “AI-only markup tricks” a weak buying claim. Use Google Search Central’s AI features guidance as a reality check.
The missing information gain is agency math: workspace design, prompt quota burn, competitor-slot pressure, evidence exports, and reporting repeatability. That is where this guide goes deeper.
How should agencies calculate prompt scale before demos?
Prompt scale is the hidden cost center in GEO tools for agencies. Before comparing plans, calculate monthly answer checks as: clients × prompts × engines × locales × run frequency. This exposes whether a vendor’s prompt allowance supports actual client delivery or only a small pilot.
Here is a simple agency model:
| Agency scenario | Clients | Prompts per client | Engines | Locales | Frequency | Monthly answer checks |
|---|---|---|---|---|---|---|
| Starter GEO retainer | 3 | 40 | 4 | 1 | Weekly | 1,920 |
| Growth agency package | 6 | 80 | 8 | 1 | Weekly | 15,360 |
| Multi-market B2B SaaS | 6 | 80 | 8 | 2 | Daily | 230,400 |
| Enterprise portfolio | 20 | 120 | 8 | 3 | Daily | 1,728,000 |
This table is not a pricing estimate. It is a workload test. If a tool prices by “prompt,” ask whether one prompt across eight engines counts once or eight times. If it prices by “response,” ask whether retries, locales, and mobile/desktop variants count separately.
The best agency pilots start with a controlled prompt set. A practical first set is 40 non-branded buyer prompts, 20 competitor comparison prompts, 10 category shortlist prompts, and 10 brand reputation prompts. If you need a build process, use this guide to build an AI search prompt set for brand monitoring, then separate branded vs non-branded prompts before reporting results to clients.
What scorecard should agencies use to evaluate tools?
Use a weighted scorecard before vendor calls. GEO tools for agencies should be scored on workflow fit, not screenshots. A good platform must separate client data, scale prompts predictably, track competitors, expose citations, produce client-ready reports, and turn findings into fixes.
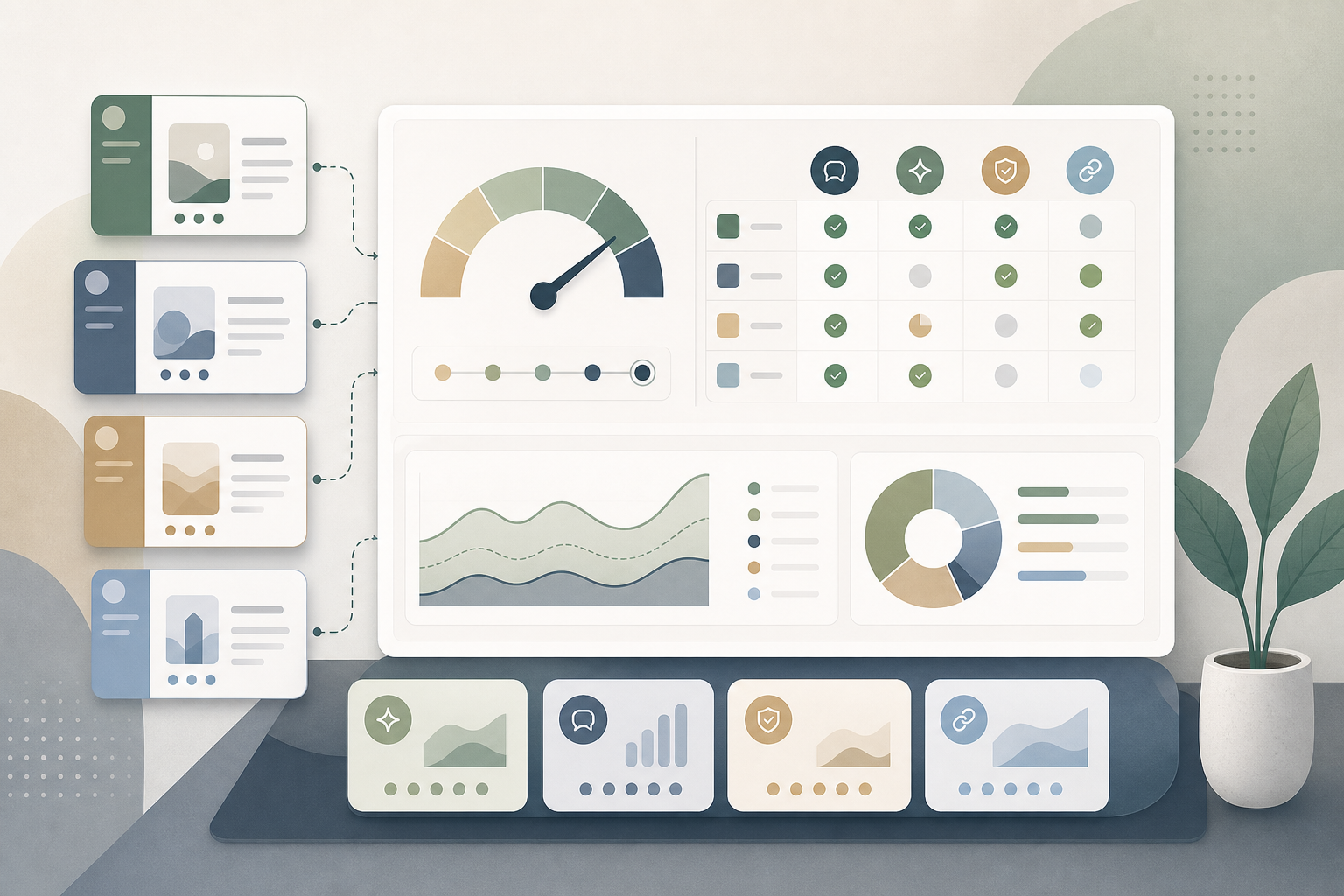
| Evaluation area | Weight | What to verify | Strong signal |
|---|---|---|---|
| Multi-brand workspace design | 15 | Can each client have separate brands, domains, competitors, users, and reports? | Client-level permissions, clean account switching, portfolio view |
| Engine coverage and freshness | 15 | Which AI engines are tracked, how often, and from which locations? | Daily coverage across major answer engines, with timestamps |
| Prompt library and scale | 15 | Can prompts be templated, tagged, localized, and reused across clients? | Bulk import, prompt grouping, version history |
| Competitor tracking | 12 | How many competitors can each client monitor without add-on fees? | Category-level and prompt-level competitor views |
| Citation and source diagnosis | 12 | Does the tool show which URLs, domains, and passages influence answers? | AI citations tied to prompts, engines, and competitor mentions |
| Client-facing reporting | 12 | Can teams export proof without manual screenshot work? | Scheduled reports, white-label options, CSV/API access |
| Fix recommendations | 10 | Does the platform tell teams what to change? | Prioritized fixes for content, technical access, citations, and messaging |
| Governance, security, and cost control | 9 | Can agency operators manage seats, SSO, roles, and usage? | Role-based access, audit logs, usage alerts, predictable limits |
A score above 80 means the platform is likely viable for a paid client package. A score between 60 and 80 may work for consulting projects but will need manual operations. Below 60, the tool is usually a research dashboard, not an agency delivery system.
Which workspace features matter most for multi-brand teams?
Workspace quality determines whether an agency can scale GEO reporting profitably. If every client requires manual setup, custom exports, and separate spreadsheet cleanup, the tool may still be useful for research, but it will not support repeatable retainers.
For GEO tools for agencies, look for these workspace capabilities:
- Client isolation: each client needs separate brands, competitors, prompt sets, users, and historical data.
- Portfolio rollups: agency leads need to see which clients are gaining or losing AI share of voice without opening every account.
- Seat permissions: strategists, account managers, analysts, and clients need different access levels.
- Reusable templates: prompt groups, report layouts, and competitor categories should be cloneable across accounts.
- Change history: teams need to know when prompts, competitors, tags, or fixes changed.
Do not accept “you can create multiple projects” as a complete answer. Projects are not always workspaces. A real agency workspace supports permissions, reporting, and billing boundaries.
How much engine coverage is enough?
Engine coverage is enough when it matches how your client’s buyers actually ask for recommendations. Most B2B and tech agencies should cover ChatGPT, Gemini, Perplexity, Claude, Copilot, Grok, Google AI Mode, and AI Overviews before treating coverage as complete.
Google’s AI Mode and AI Overviews deserve special attention because Google says they may use query fan-out, issuing related searches across subtopics and sources to develop responses. That means a client can be absent from the final answer even if one page ranks well for the obvious keyword. See Google’s AI features documentation for the official explanation.
Perplexity and Google AI Overviews often expose citations, so they are strong for source diagnosis. ChatGPT and Claude matter for recommendation language and brand framing. Copilot matters for B2B buyers who live in Microsoft’s ecosystem. Grok may matter more in categories influenced by real-time social conversation.
For each engine, ask the vendor:
- Is the answer pulled from a live interface, API, browser automation, or stored panel?
- Are citations captured when available?
- Are answers timestamped and reproducible?
- Can results be segmented by country, language, device, or buyer persona?
- Are AI Overviews and AI Mode tracked separately?
If the vendor cannot explain methodology, downgrade the data. LLM brand tracking is probabilistic by nature; methodology transparency is part of trust.
Why do competitor limits matter more than keyword limits?
Competitor limits matter because AI answers are comparative. Buyers rarely ask only “What is X?” They ask “best tools for,” “alternatives to,” “X vs Y,” “which platform should I choose,” and “what do users complain about?” A tool that tracks only one brand without category competitors misses the commercial intent.
For an agency, a normal B2B SaaS client needs at least 5–10 competitors per workspace. A crowded category may need 15. The tool should show:
- Which competitors appear when the client does not.
- Which prompts trigger competitor recommendations.
- Which cited sources support competitor inclusion.
- Whether the client is described accurately, negatively, or not at all.
- Whether competitor gains are isolated to one engine or consistent across engines.
This is where AI share of voice becomes useful. Instead of telling a client “you were mentioned 18 times,” report “you appeared in 22% of non-branded shortlist answers, while the category leader appeared in 61%.” For measurement design, see this guide to AI search share of voice.
What citation data should an agency require?
Citation data should connect answer visibility to fixable sources. The best AI visibility tool does not only say a brand was absent; it shows which domains, URLs, and passages were cited instead, then helps the team decide whether to create content, update a page, earn a mention, or correct inaccurate positioning.
Academic research supports this focus on evidence. The original GEO paper, accepted to KDD 2024, introduced GEO-bench and reported that optimization could boost visibility by up to 40% in generative engine responses, with results varying by domain. See the arXiv record for GEO: Generative Engine Optimization.
Later research also warns against assuming owned content is enough. A 2025 paper comparing AI search with traditional search found that AI search showed a strong bias toward earned media and third-party authoritative sources over brand-owned and social content. See Generative Engine Optimization: How to Dominate AI Search.
For agencies, the practical takeaway is simple: citation tracking must support work assignment. If a competitor is cited because of a third-party review page, the next action may be digital PR, partner content, review-site improvement, or a clearer comparison page. If a cited source misdescribes the client, the next action may be ai reputation management.
For a deeper buying checklist, use this AI visibility tools with citation tracking scorecard.
How should agencies test tools before signing?
Test GEO tools for agencies with a two-week pilot, one controlled prompt library, and a fixed reporting template. Do not start with all clients. Start with two representative clients: one established brand with strong SEO history and one challenger brand competing for AI-generated shortlists.
Use this pilot sequence:
- Pick 80 prompts per client: 40 non-branded, 20 comparison, 10 category, 10 reputation.
- Track at least four engines in week one and eight engines if the plan allows it.
- Add 5–10 competitors per client.
- Run the same prompt set at least twice per week to expose volatility.
- Export raw answer text, citation URLs, timestamps, engine names, and brand rank.
- Compare tool output against manual spot checks for 10 prompts.
- Build one client-facing report from the platform without spreadsheet cleanup.
- Assign five recommended fixes and check whether the tool explains why they matter.
- Estimate monthly usage from the prompt-scale formula above.
- Ask the account team to explain discrepancies, missing citations, and engine methodology.
This structure keeps demos honest. It also prevents the common mistake of buying a tool because the dashboard looks impressive on one brand query.
How do you turn AI visibility data into client-facing insights?
Client reporting should translate AI search monitoring into decisions. A client does not need 200 screenshots. They need to know where they are recommended, where competitors win, which sources shape the answer, what changed since last month, and what the agency will fix next.
| Report section | Client question answered | Evidence to include | Recommended action |
|---|---|---|---|
| Executive summary | Are we more visible than last month? | AI share of voice trend by engine | Keep, expand, or revise the current workstream |
| Category prompts | Do we appear in buyer shortlists? | Brand rank across non-branded prompts | Build or refresh category pages |
| Competitor prompts | Who is beating us and why? | Competitor mentions and cited URLs | Create comparison content or earn third-party mentions |
| Citation gaps | Which sources influence answers? | Cited domains and missing brand references | Prioritize outreach, PR, or partner pages |
| Sentiment and accuracy | How does AI describe us? | Positive, neutral, negative, and incorrect descriptions | Update messaging and correct source-of-truth pages |
| Fix queue | What happens next? | Ranked issues by impact and effort | Assign owners and deadlines |
This is also where answer engine optimization becomes a budget conversation. The best agency reports connect visibility movement to work delivered: pages updated, citations earned, technical crawl issues fixed, and messaging corrected. A later analysis can then compare AI visibility movement with conversions, demo requests, assisted pipeline, or qualified referral traffic.
A 2026 field study on ChatGPT referral traffic is a useful caution. It found raw ChatGPT referrals grew 5.7x, but untreated pages on the same domain grew 3.5x, meaning platform growth explained much of the headline lift. The intervention-aligned estimate was 1.82x, and the authors emphasized separating true lift from platform tailwind. See the arXiv study on AEO referral traffic measurement.
For agencies, that means the report should not claim “GEO drove all AI traffic growth.” It should separate tracked work, market movement, and platform-wide adoption.
What red flags should agencies watch for?
Red flags in GEO tools for agencies usually fall into three buckets: unclear data, weak operations, and risky optimization claims. If a vendor promises guaranteed AI inclusion, cannot explain how answers are collected, or suggests hidden AI-only content, slow down.
Google’s guidance is plain. For AI Overviews and AI Mode, Google says existing SEO fundamentals continue to matter, important content should be available in textual form, and structured data should match visible text. Google also says there is no special schema.org markup required for these AI features. That directly challenges vendors that sell “secret AI schema” as the main strategy.
Google’s spam policies are also relevant. Google defines spam as techniques that deceive users or manipulate Search systems, including attempts to manipulate generative AI responses in Google Search. It also names cloaking, keyword stuffing, scaled content abuse, and scraping as policy problems. Use Google’s spam policies as a procurement filter.
Downgrade any platform that:
- Tracks only branded prompts and calls that market visibility.
- Hides prompt limits until after the contract.
- Cannot export raw answers and citation URLs.
- Mixes client data in one shared workspace.
- Treats sentiment as a black box with no answer-level evidence.
- Suggests publishing mass-produced pages without original value.
- Confuses Google AI Overviews, AI Mode, and classic Search reporting.
- Provides recommendations but no way to verify whether fixes worked.
Google’s helpful content guidance asks whether content provides original information, complete coverage, insightful analysis beyond the obvious, and substantial value compared with other search results. That is the right standard for GEO work too. See Google’s people-first content guidance.
Which buying path fits your agency?
The right buying path depends on whether your agency is exploring, productizing, or scaling GEO retainers. Do not buy enterprise software to answer a question you have not sold yet. Do not use a lightweight monitor for client packages that require daily reporting, competitor tracking, and fix accountability.
Use this decision path:
| Agency stage | Best-fit tool profile | What to avoid |
|---|---|---|
| Exploring GEO | Low-cost monitoring, manual exports, limited clients | Annual contracts before offer-market fit |
| Selling first retainers | Strong prompt libraries, competitor views, citation exports | Tools that require heavy spreadsheet cleanup |
| Scaling multi-client reporting | Multi-brand workspaces, scheduled reports, usage controls | Single-brand dashboards with project workarounds |
| Enterprise client delivery | SSO, RBAC, API/export, audit trails, daily tracking | Black-box data collection and weak governance |
| PR and reputation work | Sentiment, source tracking, inaccurate-description alerts | Mention counts without answer context |
The commercial question is not “Which tool has the most features?” It is “Which tool lets our team deliver a clear monthly narrative at an acceptable margin?”
For most agencies, that narrative is built from five numbers: non-branded AI share of voice, recommendation rank, citation coverage, competitor gap, and inaccurate description rate. If those numbers are hard to produce, the platform is not yet ready for recurring client reporting.
What should your shortlist include?
A serious shortlist should include one broad AI search monitoring platform, one citation-strong platform, and one tool that fits your current SEO stack. Then score each with the same prompt set and the same client report template.
For GEO tools for agencies, the shortlist should be evaluated against actual agency delivery, not just vendor claims. Ask every vendor for the same proof:
- A sample workspace with two brands and five competitors.
- A prompt import using your real buyer questions.
- Raw answer and citation export.
- A client-ready report built without custom design work.
- A usage estimate for your expected monthly answer checks.
- A security and permission model for client access.
- A fix queue showing what the team should do next.
If a platform performs well in the pilot but fails report production, treat it as an analyst tool. If it produces a beautiful report but hides raw evidence, treat it as a presentation layer. The best fit does both.
Common Questions
Are GEO tools for agencies different from AI visibility tools?
Yes. AI visibility tools may monitor one brand’s presence in AI answers. GEO tools for agencies need extra operating layers: separate client workspaces, reusable prompt templates, competitor limits, client exports, usage controls, and repeatable reporting across multiple accounts.
How many prompts should an agency track per client?
Most agencies should start with 60–100 prompts per client. Include non-branded buyer prompts, category shortlist prompts, competitor comparison prompts, and reputation prompts. Expand only after the first report shows which prompt groups produce useful decisions.
Which engines should be included in a client package?
A strong package should include ChatGPT, Gemini, Perplexity, Claude, Copilot, Grok, Google AI Mode, and AI Overviews when available. The exact mix should follow the client’s buyer behavior, geography, and category. Do not sell engine coverage you cannot explain.
Can GEO tools help a brand get recommended by ChatGPT?
They can help diagnose why a brand is or is not recommended, but no tool can guarantee inclusion. A useful platform shows missing prompts, competitor mentions, citation gaps, and inaccurate descriptions so teams can improve content, authority, and source consistency. For common causes, see why ChatGPT doesn’t recommend your brand.
What is the biggest mistake agencies make when buying GEO software?
The biggest mistake is evaluating the dashboard instead of the workflow. Agencies need to test setup time, prompt scale, competitor limits, exports, reporting, and fix tracking. If the tool cannot support a real client month, it is not ready for a retainer.
Final recommendation
GEO tools for agencies should make AI visibility measurable, explainable, and fixable across many client brands. A good platform does not stop at brand mentions in ChatGPT. It shows where a client appears, who appears instead, which sources shaped the answer, whether the answer is accurate, and what the agency should do next.
Use the scorecard, run the prompt-scale math, and demand raw evidence during the pilot. The winning tool is the one your strategists, account managers, and clients can trust every month.